【恐山アンナ】恐山ル・ヴォワールを歌ってみた【マンキン復活】 – ニコニコ動画
【恐山アンナ】恐山ル・ヴォワールを歌ってみた【マンキン復活】(bilibili)
起因
这篇算是个随笔,随便讲讲。先从我自己的视角开始讲这些事情吧。
大概 2012 年的时候,看 B 站上有人推荐优秀的翻唱合集,误打误撞碰到了这首歌:「恐山ル・ヴォワール」。当时还不太懂日语,还没搞明白这曲子原唱是怎么回事,但 B 站上面很多弹幕都在讲这首歌原作故事《通灵王》非常感人。
到了大三的暑假我搞了个 Nexus 7 平板,于是把《通灵王》原作漫画下下来开始看。当时还是从 emule + 迅雷离线一口气下到 22 卷左右。虽然带着些心理准备,但花了几个晚上看到了原作 19、20 两卷(恐山篇)的时候还是趴在被窝里哭得根本停不下来(隐约记得及二天还约李老师去逛三好街困得不行)。
不知道为什么,感觉漫画到这里是个很好的结尾,虽然有些突然但对人物的刻画并不突兀。漫画到第 20 卷名字也叫作「エピローグ」尾声。这里的剧情大概是男主为了救人答应要退出比赛,前面很多努力就这样前功尽弃了,这时开始回忆男主和女主相遇时的故事,这段故事正是“恐山篇”。作者武井宏之这段故事描绘得非常完美,让我觉得男主做出这样的选择完全不奇怪。后面又继续出了好多卷反而有种编辑强行续命的感觉。
恐山篇之后的漫画我也没有继续看下去。感慨这个短篇真的是看过的作品里质量相当高的一部,即便没有前面任何铺垫这也是质量极高的漫画。我个人是极其推荐的。即便后面想补,每次试图看到这里眼泪就止不住得流。
虽然记得这首很好的曲子和很好的漫画,当时距离今天也已经十年了。朋友一直不推荐这部作品的动画,因为明显烂尾。所以后面突然听说这部作品要重新动画化还是有些震惊。2021 年的时候新动画播出,前几集的时候问又去问朋友这部质量怎么样,得到的答案是,节奏飞快,质量微妙。当时还是没有去看。
去年(2022)年底疫情宅家的时候又想找点长篇动画看,看到网上纷纷评价新动画里面恐山篇处理极其优秀。终于开始从头补,花了些时间看完之后才发现,这新动画完全就是为了恐山篇而诞生的。再后面甚至意识到,这后面作者、声优们的一切努力,从这首歌作为起点,可能都只是为了让这个优秀的短篇部分展示在荧幕上。而新动画也确实很好地完成了这个任务,给几乎所有人一个可以接受的结果,走到了属于作者不完美但也不错的结局。
而今年因为自己的原因换工作,正好有一个月左右修整的时间,本来想留一周去种子岛但没去成,想了下就把目的地改成了青森,去了在日本第二想去的地方——恐山。
旅途
端午节陪几个同学在关西玩了几天之后直接坐新干线从京都北上来到青森,修整一晚上之后从青森出发乘坐青い森鉄道前往むつ市的下北駅。去往恐山巴士的发车时刻表与电车是匹配的,从车站出来之后左手边就会看到前往恐山的巴士就在下北駅前等待出发。
恐山作为日本三大灵山,有很多人会因为佛教的原因过来参观。我发现大多数游客都是中老年人,像我这种圣地巡礼的人估计并不多。为了方便旅客,上车的地方会售卖往返乘车券方便找零。另外电车站出来会有 coin locker 方便旅客存包,但位置有限先到先得。


上山的巴士差不多全程要 40 分钟,在上山路上有一站叫“冷水(ひやみず)”,司机会在这里停车让车上的 乘客下去尝一下这里非常美味的山泉水。传说“1杯飲めば10年、2杯飲めば20年、3杯飲めば死ぬまで若返ると”。注意下山是不会在这里停的,推荐大家下车去试一下。
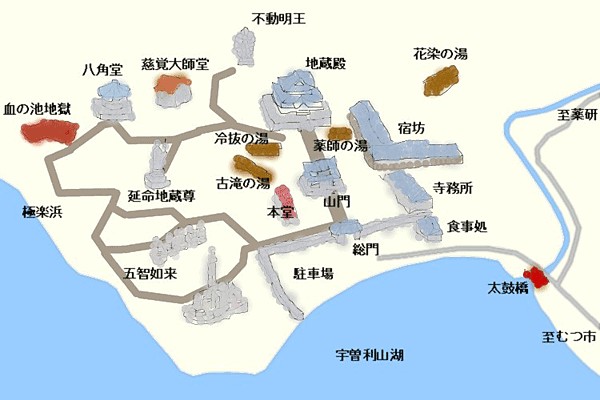
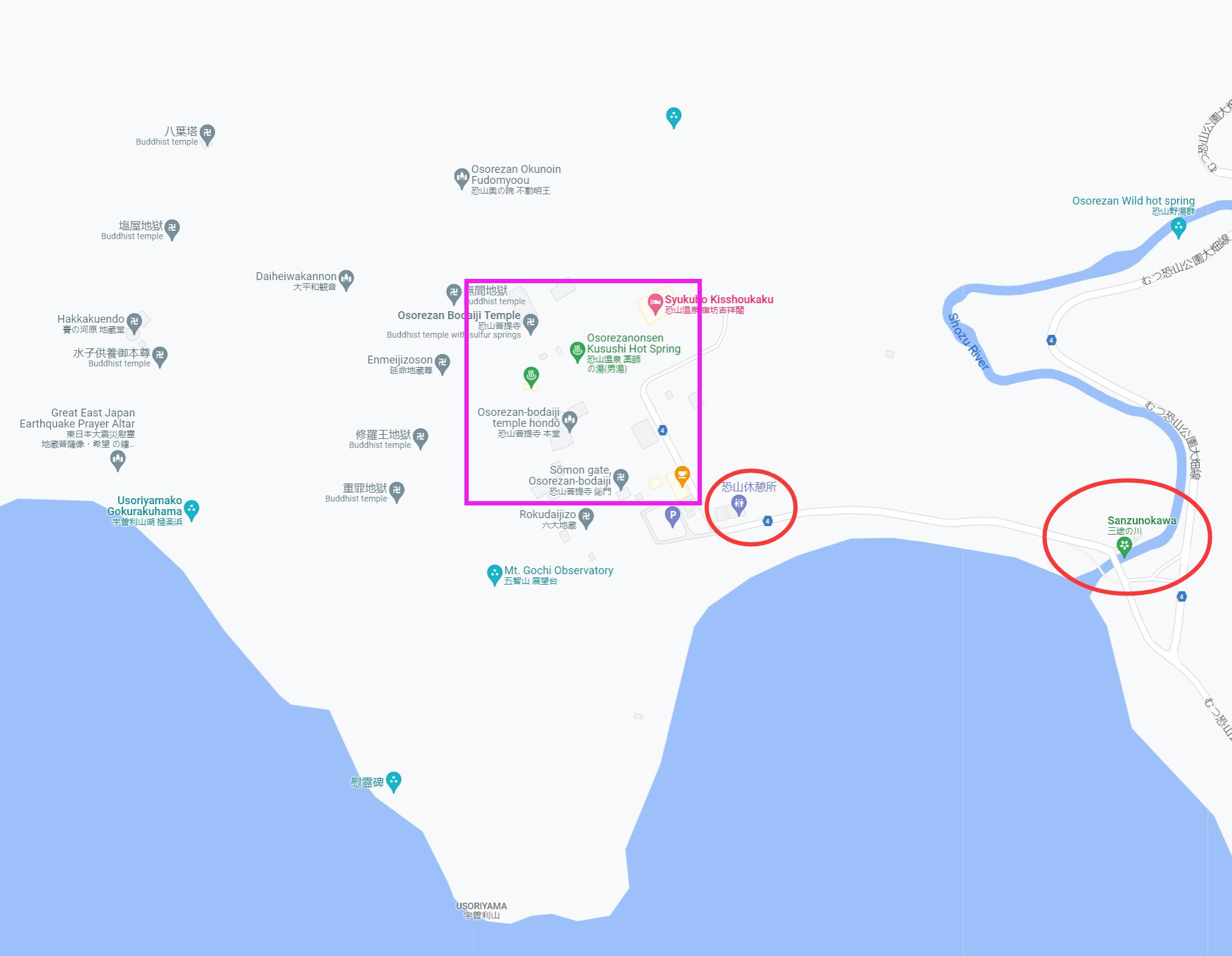
车到终点后到达恐山休憩所。建议可以先往回走一点,到地图右边的“三途川”。这里有一座太鼓桥,由于桥太老因此现在已经不让人直接走了。另外从恐山休憩所到太鼓桥中间路上看火山湖的景象也比较震撼。


回到恐山菩提寺的入口,寺院外左手边有“六大地藏”。入口正常买票就可以进入恐山菩提寺境内了。


动画中对寺院内部的描写并不多,基本都只集中在“山门”部分。上面印着“灵场恐山”的字样。


整个寺院区域其实还有几个温泉,有些温泉可以混浴,但我当天没带毛巾就没敢进去。继续往里走就可以看到非常有特色的火山岩地貌,也是这里被称作“地狱”的原因。有些地方还能看到石头在向外喷出气体。




走到最里面可以看到动画中同样出现过的宇曽利湖的景色。


走完一圈之后其实发现恐山寺院里面的区域并不算很大,一个小时左右的时间就可以逛完。但里面的景色确实比较有特点。有兴趣的可以考虑花点时间去泡免费的温泉。中午可以到正门外面的食堂吃饭。之后坐返程的巴士就可以回到下北车站了。


总结来说,动画里真正对恐山这个地方的描绘并不多。我自己这次来恐山感觉作为游客的心态更加被满足,看到了之前从来没有见过的景象我非常的开心。而这次旅程,对我来说这更像是一个精神意义上的终点,来过之后能够让自己之前对《通灵王》这部作品的情绪画上一个句号。
总结 – 另一个视角
一直感觉新的《通灵王》动画就是为了恐山篇能够在屏幕上出现,所谓“为了这盘醋包的饺子”。我觉得这里正好可以换一个视角,看看恐山篇动画到底是如何一点一点走到观众面前的吧。
- 1998年6月,武井宏之的《通灵王》漫画开始在周刊 Jump 上连载。
- 2001年7月,旧版的《通灵王》动画开播,恐山安娜的声优林原惠演唱了里面绝大多数的主题曲
- 2002年5月,恐山篇部分的单行本第19卷发售。
- 2002年9月,TV 动画以几乎腰斩的方式完结。
- 2004年8月,漫画腰斩停止连载。
- 2010年3月,V家P主かぴたろう在nico上发布了初音未来演唱的歌曲「恐山ル・ヴォワール」,歌词完全使用原作中恐山篇的诗句。武井宏之在 Twitter 上盛赞了这首歌并表示如果有机会把恐山篇动画化,一定会用作片尾曲。
- 2011年10月21日,nico 上出现了一个以“恐山安娜”为 ID 对前面初音歌曲的翻唱投稿,纪念漫画连载恢复,也就是这篇 Blog 最开头的链接。发表10天播放量超过70玩,这首歌是2011年的nico翻唱视频播放数量冠军(因为真的是“翻唱”初音的曲子)。
- 2011年11月,林原惠发文承认了上面那个视频是她本人唱的,也介绍了一些歌曲背后的小故事。
- 2018年3月30日,林原惠的第14张专辑 Fifty~Fifty 发售,作为商业CD首次正式收录了林原惠(恐山安娜)演唱的「恐山ル・ヴォワール」。
- 2020年6月,官方宣布新版本动画制作决定。
- 2021年4月,新版动画正式开播。新作动画除男主外其他全部角色都保持了与20年前版本一样的人选,实属难得。也有说法表示这正是新作动画拖了很久才定下档期的原因。
- 2021年11月,恐山篇部分(30~33集)试映及正式放送反响热烈,第33集的片尾曲使用了林原惠演唱的「恐山ル・ヴォワール」。
- 2022年4月,新版本动画52集正式完结。
正是这二十多年发生的这些事情让我相信,大家可能真的只是希望恐山篇能够顺利动画化,能够以它本来该有的姿态来到观众的面前。
所以这也算是安利这部漫画、这首歌的一篇 Blog。纵使以今天的标准来看,长篇动画已经毫无吸引力,但只论恐山篇的剧情,不论漫画、还是歌曲,都还是极其优秀的作品。希望更多的人能够听完林原惠的这首歌。
当然,因为这次游览起因是换工作。这对我个人来说也算是一个人生阶段的终点。
Reference & Useful Links
- 官方的观光介绍 恐山 – 下北半島の観光 | 下北ナビ
- 巴士的时刻表 http://www.0175.co.jp/s/s-bus/ 选择“恐山线”
- 林原惠本人对于翻唱的解释 – http://king-cr.jp/artist/hayashi/news/2011/1108.html