2021.09.26 补充:原文在 2011年10月31日发表在之前的 Blog 上,本文是基于 Internet Archive 上面的记录手动迁移过来的内容。
以下为正文:
本文原创,转载请注明出处: http://atarss.com/blog/?p=193
计科无能者无视第一段,着急写作业的建议不用看第三部分,直接用第二段的方法。
KMP的实质是自动机匹配的优化,即不需要构造自动机,而通过模式字符串的自我匹配来简化过程,使预处理的时间复杂度降为O(m)。
1.字符串匹配的过程;以及为什么我们能优化算法
假设要被搜索的字符串是”bacbababaabcbab”,要搜索”ababaca”这个串。

浅绿色的表示已经被匹配的字符,我们定义正在被匹配的长字符串里面的位置是i=5,要搜索的模式串已经匹配到j=6第6个字符而且与原始的字符串不匹配。按照朴素的匹配算法,我们应该让i++,即从i=6开始匹配。但是我们已经知道i从5~9与B串的j=1~5是完全相同的。因此即使我们不知道A串的内容,只通过B串的内容以及我们已经匹配到第6个字符这两项数据,就可以知道从i的下一项数据一定是不匹配的。
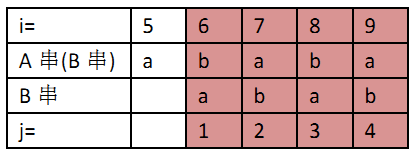
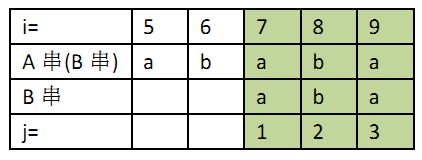
同理我们知道主串在i=7时的匹配可能是成功的,因此我们可以设计算法不去匹配i=6时的情况而直接跳到i=7去匹配,而且右移2位这个数字2只是通过B串(要搜索的串)的自我匹配来完成的,也就是可以在匹配前完成计算。而这就是KMP较朴素匹配算法的优化之处。
2.如何计算当不匹配时主串要移动多少位
依旧要搜索这个串”ababaca”,我们已经知道要跳过多少个字符的字符数量是与要搜索的字符串(A串)无关的,实质是要搜索的串(B串)的自我匹配。而这个信息可以被预先计算出来并被存储起来。
每次偏移多少位显然与匹配到B串第几个字符时开始不匹配的j位置有关,因此我们定义一个数组来存储这个偏移量的信息,定义为D[1..t],t为B串的长度,下标从1开始。
※我们前提假设,每个字符只能读取一次,真正的字符指针不能后退。
实质即为,假设当匹配到j=n时不匹配,即j从1~(n-1)都是匹配的,那么偏移量就是字符串从后向前自我匹配时到达前面之前所能达到的最大的位置。举例:

按找从下往上看的顺序就能找到偏移量,显然最长的匹配的偏移量为2。按照这种方法就能找到所有的偏移数组的值。
若j=1时不匹配,毫无悬念,偏移量为1,;
若j=2时不匹配,则右移一位也没有意义,直接右移两位,偏移量为2;
若j=3时不匹配,i=3与j=1时相同,因此偏移量为3-1=2;
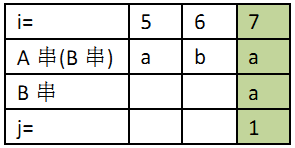
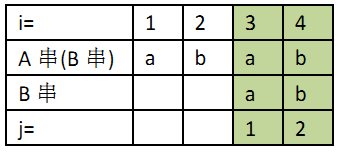
若j=4时不匹配,同理得偏移量为2;
j=5时上面已经分析过,偏移量为5-3=2;
j=6时,同理,偏移量为6;
j=7时,偏移量为7-1=6;
在计算的过程中,我们知道,真正找到的并不是偏移量,而是最长真字串的长度。我们成这个关于j的数组(函数)为前缀函数Pi[j]。
3.前缀函数的递推计算
根据上面的算法,我们同时得到前缀函数的值

下面说明递推的过程:
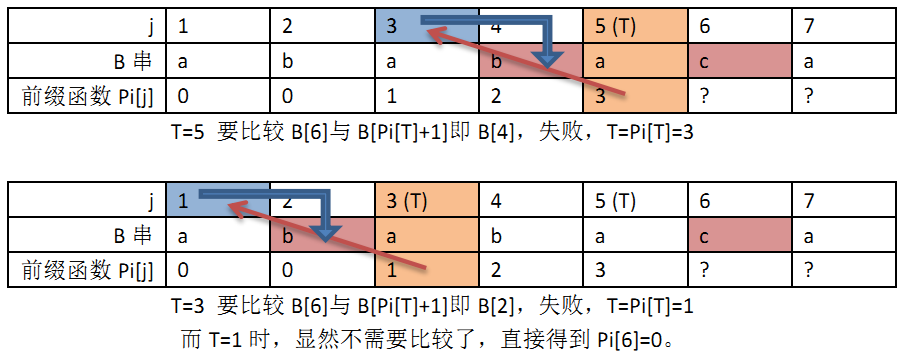
假设我们已经知道了j=1~4时Pi[j]的值了,如何推得Pi[5]和Pi[6]呢?

Pi[4]=2,说明字符串B[1..2]与B[3..4]相同,又B[5]==B[3],所以,P[5]=P[4]+1=3;
而Pi[6]却不等于Pi[5]+1,这是因为B[4]≠B[6],因此没法通过Pi[5]+1得到Pi[3],但同时,B[1],B[3],B[5]均为字符’a’,或许还可能通过Pi[3]或Pi[1]得到Pi[6],但一次次匹配都发现B[6]不等于B[4]且B[6]不等于B[2],这时,Pi[6]只能是0。
抽象一下,就得到Pi[j]的算法:
先用一个临时变量T=Pi[j-1]
若B[T] == B[j],那么Pi[j] = Pi[j-1]
否则,T=Pi[T],继续上面的操作,直到Pi[T] == 0,这时Pi[j]=0。
最后附上计算Pi[6]的示意图:
最后一部分参考了M67的文章,在此对其表示感谢。