继去年去过恐山之后,今年五一假期来日本看 Live,正好有时间可以前往种子岛。种子岛是我在日本最想去的地方(没有之一)。五年前(2019)第一次去九州因为时间原因没能去成种子岛,去年休整的那段时间也因为没能提前预定好整个行程导致放弃,而终于今年有机会踏上这个神奇的地方。
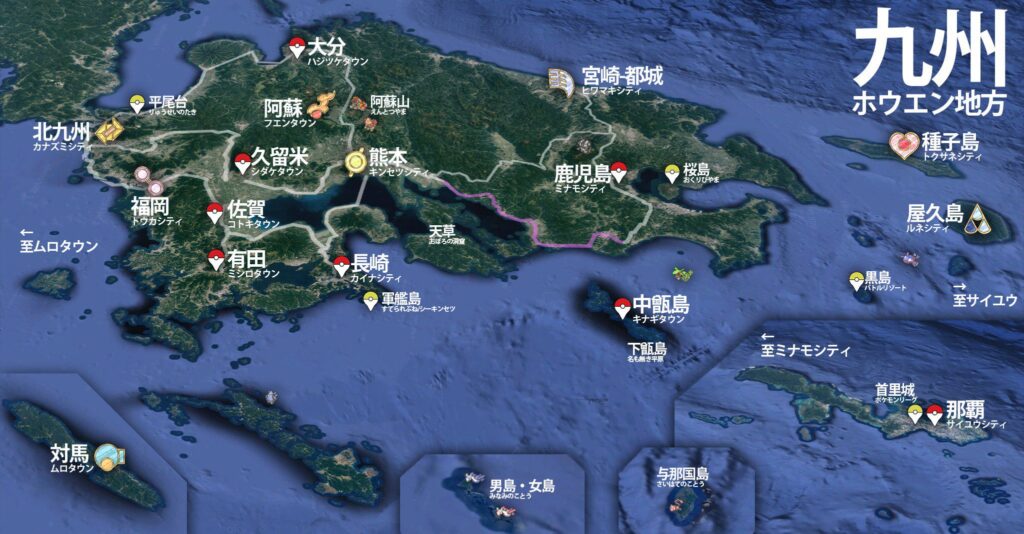
虽然种子岛大量用圣地巡礼来宣传自己的旅游资源,但实际上它在 ACG 出现的次数并不多,大多数人的印象里只有《秒速五厘米》和《机器人笔记》两部作品。离开动画,种子岛主要知名于两点:首先 16 世纪葡萄牙人碰巧来到这里,把西方的火枪技术传给了日本,九州萨摩藩也因此在一众诸侯里成为一个军事强国;另外上世纪战后日本尝试寻找一个尽量离赤道近的地方作为火箭发射基地,种子岛的航天中心也成为了目前日本使用最多的火箭发射场。后者使得种子岛会出现在科技 / 科幻题材的作品里面(“离宇宙最近的地方”)。
这次行程我并没有特别去考虑“圣地巡礼”的部分,而是单纯把种子岛当作航天中心火箭发射场的周边来考虑。行程里没有特地包含其他人写过的《秒速五厘米》/《机器人笔记》圣地,很多是纯凭兴趣瞎逛,但也因此增加了许多我觉得有趣的见闻。
一、制定计划
今年年初买碟子尝试抽选 Poppin’Party x MyGO 的 Live,二月底发现自己中了之后便开始安排五一前后的整个行程。虽然提前三个月,但订行程中间过程还是让我非常痛苦,对我来说种子岛最大的挑战是订酒店,在 agoda / rakuten travel 上搜到的选项还是非常少的,很多会让我觉得价格 / 位置不合适(只能自驾开车过去)。后面实在觉得没办法了开始对着西之表市 / 南种子町的市政网站一个一个去找网站联系方式,最后是广撒网发邮件的方式找到了合适的住宿。由于我希望第二天去航天中心方便一些,因此考虑住在了离航天中心更近的南种子町而不是人最多的西之表港。另外航天中心的巴士讲解参观虽然免费,但预约参观还是需要打国际长途。把住宿和航天中心预约搞定之后,剩下的交通(飞机 / 船票)就比较简单了。基本上提前三个月的时候整个行程预约就都搞定了,在我看来如果更晚预约的话很可能会变得非常麻烦。
总结来说,挑战包括:
- 严苛的时间:种子岛的公共交通只有平日开放,没法自驾的话出行时间会因此受限;
- 较少的住宿选项:考虑放弃用在线预订平台、而是回归传统的邮件 / 电话预定;
- 沟通成本:对日语不好的人沟通成本要高很多。
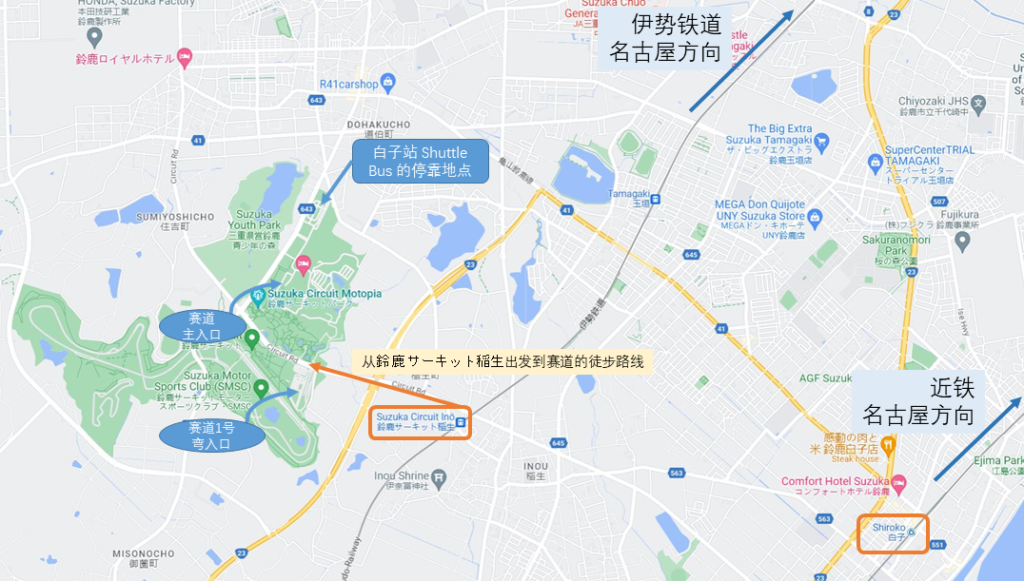
这里简单画了一个地图介这次的行程:
- 飞机前往种子岛机场
- 机场乘公共交通(目前是拼车的出租车)到达西之表市
- 西之表市乘公共交通到南种子町,然后换乘南种子町的巴士来到航天中心
- 参观完航天中心后出租车去南种子町的其他地方观光
- 乘巴士到西之表港,乘船返回种子岛
二、种子岛机场
如果按照 Wikipedia 的说法,目前使用的种子岛机场是 2006 年启用的新机场,而之前使用的前代种子岛机场是《秒速五厘米》出现过的地方。新机场对我这个没飞过支线飞机的人来说非常新奇。这次乘坐的 ATR42-600 飞机是我人生中第一次乘坐的螺旋桨飞机。飞机下降时为了对齐跑道角度会绕岛大半圈,可以看到整个种子岛的风光,天气好的时候景色非常优美。



等行李的时候可以看到机场里面有一些 JAXA 的宣传窗口(卖周边)。需要注意的是从机场到街区的交通:之前在制定行程的时候还有从西之表市 / 南种子町往返机场的巴士,但大概由于现在乘客太少,从 2024 年 4 月开始改成了需要预约的拼车出租(乗合タクシー),价格虽然没有变化但需要提前一天以上打电话预约,还是稍微麻烦了一些。
拿到行李离开机场就可以找到之前约好的出租,路上只有一个游客跟我们同行,然后便来到我们的第二个目的地——西之表市。
三、西之表市
首先来到的是西之表港的游客中心,意外地里面人不少,应该都是在等待乘坐高速船。游客中心对我来说比较方便的是可以存放行李(需付费)。看照片就会发现这地方真的很用力在强调自己“动画圣地”的属性。


到达西之表港还只是中午,因此找了边上一个旅馆吃午餐,正是我之前根本没定上的旅馆,人果然不少。之后便进入了“来都来了总得找点地方去”的心态,便开始寻找步行能及的目的地,决定去看看边上的“铁炮馆”。

说是“铁炮馆”,实际上则是这个小岛自己的史料中心,里面一部分讲自然,说有许多化石在这里发现,有许多上古火山喷发的线索在这里可以被找到;另一部分则讲人文,差不多五百年前葡萄牙人第一次来到这里把火绳枪传给了日本,开启了历史的新篇章。对我来说最有趣的事情是了解到九州其实曾经在七八千年前遇到过一次巨大的火山喷发,导致九州在之后的数百年都不适合人类居住,许多人逃到了更远的地方;考虑到日本语言 / 文化的来源长期没有什么定论,这个事实还是非常有趣的。


之后沿着小路往北前往海岸,步行看了看沿途风光,发现里路边似乎有很多野生的百合花,后面才知道这种叫做“铁炮百合”实际上是西之表市的市花。后面与第二天的出租车司机聊天提到这个物种最开始来自沖永良部島,爱称叫做“えらぶゆり”,在整个种子岛到处都很常见。之后沿着海岸线走回到西之表港,乘坐岛上的巴士前往南种子町去订好的酒店 Check-in 之后便结束了第一天的行程。
四、种子岛航天中心


// 宇宙中心这个名字原封不动搬出来太容易让人误解了,仿佛是五道口一样;还是称它为航天中心吧
在南种子町的旅馆住了一晚后,第二天一早乘坐南种子町的 Community Bus 来到种子到的航天中心,这便是这次行程的核心部分了。航天中心本身对外开放的部分其实只是外部一个类似科技馆的设施(宇宙科学技术馆),虽然做的很用心但介绍的东西极其有限;种子岛这里的特殊奖励是你可以提前预约一个免费的 bus tour,有专门的讲解员带着你在巴士上穿梭在真正的火箭发射场工作区域中。事后来看这个免费的设施介绍讲解实在是赚爆了(比那些打卡圣地巡礼有意思多了)。
按照最开始预约的时间,Bus tour 会在上午十点半开始,而乘坐一天最多四班公交车差不多九点出头就到宇宙科学技术馆了,因此可以先有一个小时逛科技馆的时间。之后在门口大厅集合乘坐巴士即可。发现一同集合的人里面外国人除了我还有好几个,而解说显然只有日语,大概率大家都是懂日语的。
Bus tour 分为三个部分,首先是来到 (M) 观景台,可以远望题图里面的景色 (A)。之后会来到 (K) 火箭仓库(ロケットガレージ),这里可以看到火箭一二级以及火箭引擎的实物。到这里看是就已经感觉有点震撼了,虽然不是想象中巨大的实体,但能如此近距离的接触到火箭实物还是很难得的经历。解说员会详细介绍火箭发射前后的过程,了解日语的话还是能感受到不少信息量的。最后会来到 (O) 发射指挥中心(総合指令棟),可以非常近距离的看到以往电视中才会见到的大屏幕控制台,虽然不可以拍照但可以看出里面的设施已经相对陈旧,不少极其古老的电脑仍在参与控制任务。
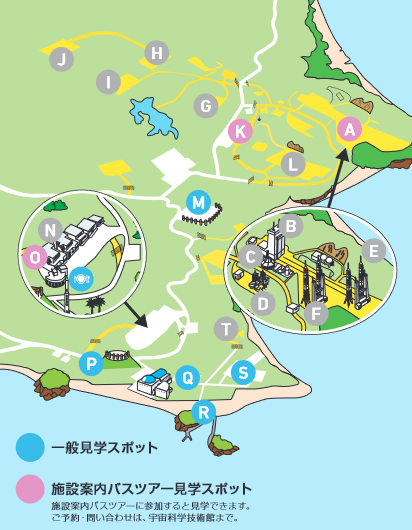



参观结束之后还可以作为游客前往 JAXA 的食堂吃午餐,要跟 JAXA 的工作人员一起排队打饭还是非常难得的体验。之后很从食堂出来也可以顺路再看看控制中心相关的景象,这次信息量巨大而且基本没有什么限制的航天中心之旅就可以结束了。


五、南种子町
时间来到第二天的下午,继续秉承着“来都来了不出去逛逛就亏了”的心态,但又同时纠结公共交通不知道去哪里合适的我,打起了出租车的主意。搜到了一个当地出租车会社的电话,打过去说我是游客想到处逛逛,一辆出租车便很快过来接我了……


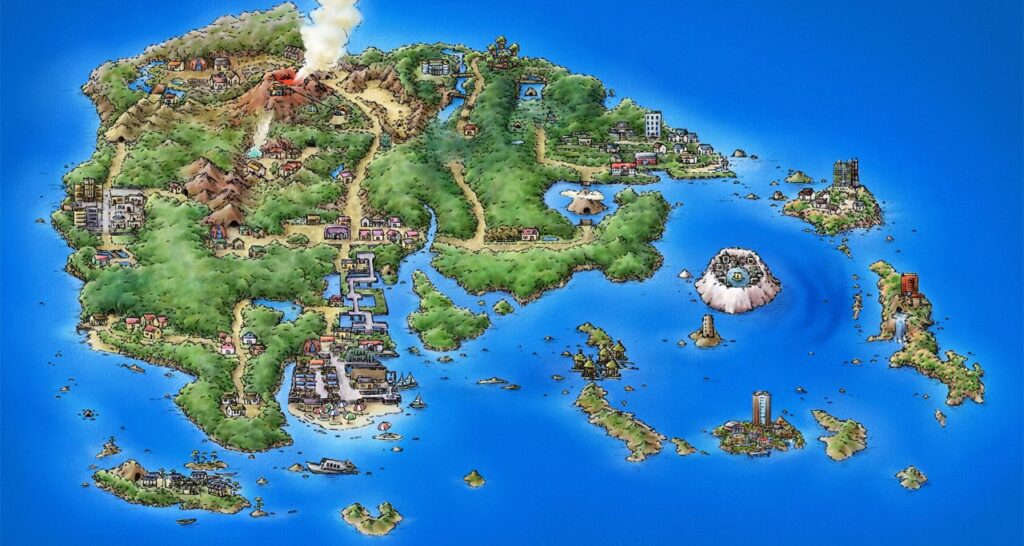
但实际上下午的行程也没有提前安排,想到哪里就去哪里,于是便找了两个还算近的景点瞎转一圈。一个是整个种子到的最南端門倉岬,算是个普通的观景台,然而当天天气很一般能见度也不算好所以去了感觉比较亏;另一个是涨潮无法进入但落潮可以看到里面巨大空间的海边岩洞千座の岩屋,这个就比较有趣了,如果你玩过 Pokemon G3 宝石系列的话应该记得第七个道馆所在的城市有一个火箭发射中心的同时,还有一个潮汐洞穴;没错,那个岛屿的原型正是种子岛。这个经历让我感觉我好像也算是另一种圣地巡礼——给 Pokemon 的圣地巡礼。除此之外还路过了一个《机器人笔记》里面登场过的公园宇宙ヶ丘公園,也算是再次给这次旅行增加一点点圣地巡礼的属性吧。


出租车司机还是很健谈的,给我讲了不少岛上的细节,比如前面提到的百合花,还有提到整个种子岛南端其实在二战的时候修建了不少军事设施(我怀疑 Google Maps 上看到很多灰底的区域就与此有关)。聊天时有一个话题倒是说得很好,日本这边基本上是不会主动管你来看所谓的敏感设施的,这边大多数路人也不会像朝阳群众那样管太多,也因此我才有机会能近距离来到航天中心看到这么多有趣的见闻。
六、尾声
下午出租车回到旅馆然后便准备思考晚餐了,晚上依旧去南边随便逛了逛但没有太多收获,只是感慨种子岛这个小地方大概是我来日本的旅行里去过最“村”的地方,如果不是航天中心这里大概率只会是人口逐渐流失的海边小岛,惨淡经营着潜水等旅游业。晚上吃过晚餐后毫无娱乐活动,除了修图刷 SNS 之外实在无聊,第三天一早便乘坐早上6点左右的巴士直接前往西之表港去坐高速船回归现代社会了。


其实路上还有很多有趣的见闻,坐巴士从西之表港岛南种子町要一个多小时,但两次坐车都会看到两个 JK,感觉大概率是通勤去上学的,仔细想想每天通勤接近三个小时也是非常痛苦。南种子町我住的旅馆的老板娘非常热情好客,仔细给我介绍很多东西,这里也安利一下:ビジネスホテル サンライズ
最后备注下:另外前面提到 Pokemon 的事情,其实整个九州都是 G3 丰缘地区的原型,正好最后拿一张宇宙科学技术馆大厅地面的地图强调一下。对我来说第一次知道航天中心正是 Pokemon 这部游戏,而后面鹿儿岛紧接着的九州之旅也依旧是一种圣地巡礼,就不在这里继续展开了。