接上一篇 CLIP 的文章,我自己在搭建个人图像搜索引擎的过程中还有搜索图片中文字的需求,其实技术部分比较水,自己想要的多语言 Feature 完全没时间去尝试,就算是填坑把之前的内容补齐,也算是一个简单的笔记。
本文内容包括:
- 搜索文字的需求从何而来?
- 个人使用 PaddlePaddle 的 Best Practice 与限制
- ES 作为的文本检索后端的选择
- 效果展示,与 CLIP 搜索的对比分析
- Limitations & TODO
背景
沿着上一个自己架在 NAS 上的服务,我这边还有其他搜图的需求,包括但不限于:
- 想搜一些表情包,但只知道上面的文字,或者图片主题很难用 CLIP 关键字描述
- 找一些聊天记录截图里面群友发的黑历史,这时候只能搜群友 ID / 用户名
- 想找一些包含特定编号 / 编码的内容(比如我的用户名、邮箱、电话、航班编号等等,这些在 CLIP 里面是没有语义的)
怎么做呢?前面已经写过图像存储和搜索前端了,想了下找个开源的 OCR 模型应该就能做到这一点。另外文本检索不是我熟悉的东西,所以还得找一个支持文本检索的后端服务,这里我选择了 ElasticSearch。
PaddleOCR 模型的使用
按照周围同学同事的说法,PaddleOCR 基本是开源 OCR 模型里面易用性和性能 Trade-off 做得最好的,最初部署基本上参考他们的 github 页面即可。
这里需要注意的事情是他们的库参数还是有点多,有一些内容还是有点缺乏文档需要自己去试。
多语言部分,我尝试了一些他们提供的多语言模型,感觉就只有默认的汉语 + 英语模型性能是最好的,宣称的多语言感觉不管怎么搭配都会损害原始汉语 / 英语的性能。按照其他同学测试感觉还是 Google Android Demo 里面的多语言 OCR,或者使用 PaddlePaddle 另一个项目的 PULC 多语种分类模型可能才能达到还不错的效果。
总之我对 Paddle 自带的多语言不是太满意,毕竟我想一个配置直接无脑解决汉语+英语+日语多语言场景,这里就只能退一步先无脑用他们的汉英模型。模型下载部分可能需要注意下本地模型的加载:自己在开发机器时会发现模型名称按照文档写就可以,反正回自动下载;但如果要在非联网机器的话需要到他们的 model list 页面手动下载到本地解压,加载时也要注意目录结构。
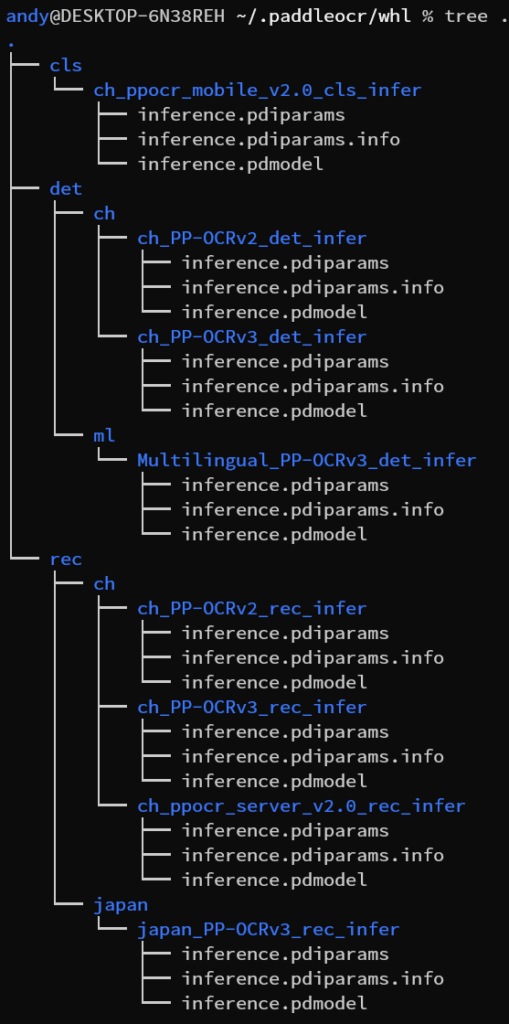
在上面目录结构下,加载模型的代码如下
from paddleocr import PaddleOCR
ocr_model = PaddleOCR(
ocr_version="PP-OCRv3",
# det_model_dir="/home/andy/.paddleocr/whl/det/ml/Multilingual_PP-OCRv3_det_infer/", # multi-language
det_model_dir="/home/andy/.paddleocr/whl/det/ch/ch_PP-OCRv3_det_infer", # Chinese
# rec_model_dir="/home/andy/.paddleocr/whl/rec/ch/ch_ppocr_server_v2.0_rec_infer/", # chinese model on server
# rec_model_dir="/home/andy/.paddleocr/whl/rec/japan/japan_PP-OCRv3_rec_infer",
rec_model_dir="/home/andy/.paddleocr/whl/rec/ch/ch_PP-OCRv3_rec_infer", # Chinese model
# use_angle_cls=True,
# lang="ch",
) # need to run only once to download and load model into memory
使用模型的代码如下
try:
ocr_result = ocr_model.ocr(img=image_path, cls=False)
except:
print("Error: ", image_path)
continue
ocr_str = ""
ocr_full_result = []
for idx in range(len(ocr_result)):
for line in ocr_result[idx]:
ocr_str += (" " + line[1][0])
ocr_full_result.append(line)
ocr_str = ocr_str.strip()
ElasticSearch 文本搜索的使用
之前基本没用过 ES,也是一边踩坑一遍试,感慨现代数据库系统坑是真的多(我还丢了一次数据)。多语言感觉自己没找到好办法,还是先当只有汉语的场景来处理吧。
其实用 ES 之前试了下 MongoDB 自带的中文检索,唉,一团糟……因此想着直接 ES 一步到位吧。
首先是建立中文索引,安装最新版本(我是 8.7.0)之后需要手动安装中文 smartcn 分词插件,来到 ES 安装目录下:
sudo bin/elasticsearch-plugin install analysis-smartcn
之后重启 ES 并建立中文索引,我用的 python 接口
from elasticsearch import Elasticsearch
es_client = Elasticsearch("http://10.0.0.11:9200")
ret = es_client.indices.create(index="ocr_text_result", body={
'mappings': {
'properties': {
'ocr_text': {
'type': 'text',
'analyzer': 'smartcn',
},
"filename": {
"type": "keyword",
}
},
},
'settings': {
'analysis': {
'analyzer': {
'smartcn': { # 使用 smartcn 分词器
'type': 'custom',
'tokenizer': 'smartcn_tokenizer'
},
},
'tokenizer': {
'smartcn_tokenizer': { # 定义 smartcn 分词器
'type': 'smartcn_tokenizer'
}
}
}
}
})
之后导入文档即可
ret = es_client.index(
index=ES_INDEX,
body={
"filename": filename,
"ocr_text": ocr_text,
}
)
ES 的检索效率可比上一篇 CLIP 搜索高多了,基本可以控制在 1s 以内。不过因为 ES + Mongo + CLIP Model 我直接给我 NAS 加到了 32G 内存……
效果对比 / 展示
先是要搜图,最近大家都在吐槽五一调休,正好用关键词找了个表情包。
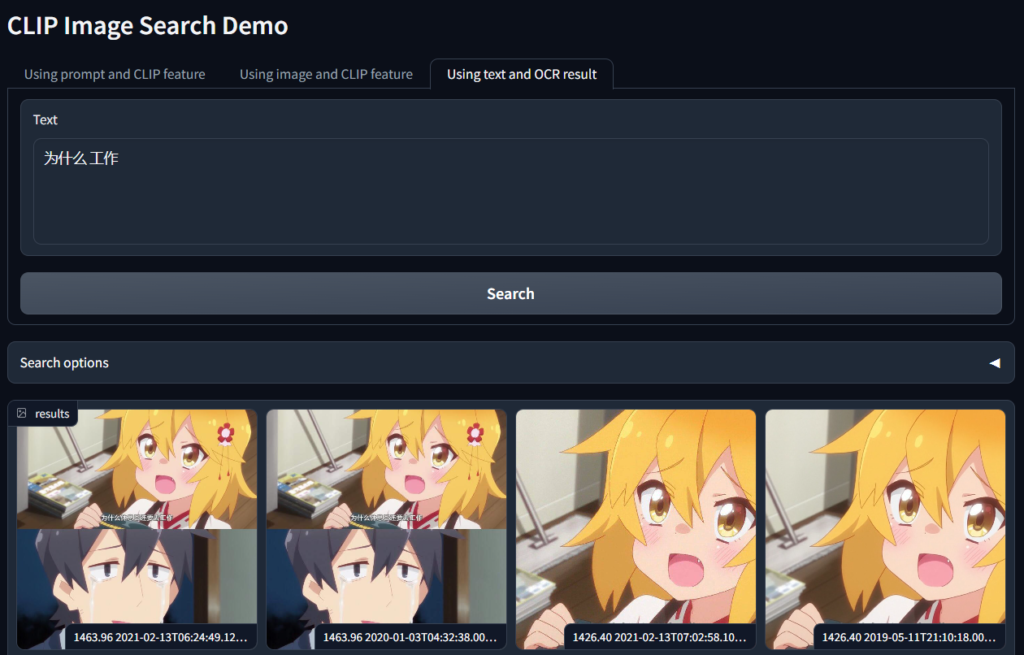

另外,还有些不太适合展示但是确实很方便的场景,包括:
- 找群友发言黑历史(甚至包括自己)
- 找自己的地址订单门票截图
- 找之前坐过航班的机票 / 截图(比如我发现我竟然三年坐过三次 NH961 这个航班,还有两次日期都是相同的只有年份不同)
虽说 OCR 解决了不少 CLIP 时候的问题,我觉得这只是搜索工具的一部分,CLIP 和 OCR 感觉互相各有些无法替代的功能吧。
最后我发现 Google Photos 也有 OCR,就是……好像没那么强,不是很显眼(
Limitations & TODO
// 写到这里我明白我只是在挖坑不填
多语言是我想花点时间去解决的事情,不过目前看可能要尝试的东西有点多。语种分类模型 + 文字识别的思路其实最开始来自 Android 上的一个应用叫 fooviewer,从里面集成了 Paddle 的模型但不是 OCR 才发现这个思路。
Epix 帮忙尝试的 Android Demo 效果如下图,其实还可以。有点类似另外一个人用 iphone 做 OCR 后端的思路,所以没有用的主要原因是我还得连个手机(但我真的有个不用的 iphone SE)

另外即便多语言 OCR 做好之后,还有后面分词、文本检索的问题。目前看任何一个搜索引擎后端系统上多语言的处理都不是很显然,有精力的时候再去想这件事请吧(
OCR 效率,检索效率目前看问题不大,速度什么的完全可以接受,可以先苟着。